|
|
|
|
|
|
|
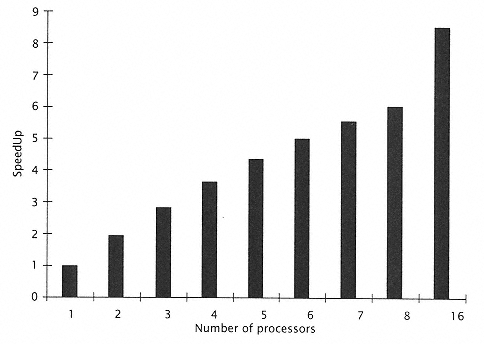
Figure 10.25
Speedup relative to one processor. |
|
|
|
|
| Baseline Processor with CBWA Cache |
| | Level one cache miss ratio |
| 0.01 | | Level one cache line size |
| 128 bytes | | 348 ns |
|
|
|
|
|
|
In a multiprocessor system, given an application that can be partitioned appropriately, we generally want to have linear increases in performance. This means that as we scale the system from 1 to N processors, the performance of the N processor system should be N times that of the single processor system. However, this usually is not true in real life, and one of the limitations is the shared memory bus. |
|
|
|
|
|
|
|
|
As can be seen from Figure 10.25, the increase in performance decreases as the amount of bus contention increases. This contention is taken into account by incorporating the wait time in the memory access time. |
|
|
|
|
|
|
|
|
Figure 10.26 shows the best CPI across feature sizes. At the 1m feature size, the bandwidth supplied is not sufficient to match that of the multiprocessor implementation. This results in a dramatic drop in CPI for the multiprocessor case as we go from 1m to 0.75m. It can also be observed that the increasing cache size does not help the baseline CPI much after 0.75m. With this observation, one should consider moving to either superscalar or multiprocessor architecture. This coincides with what is happening in the industry. To decide between the superscalar and multiprocessor cases is a |
|
|
|
|
|