|
|
|
|
|
|
|
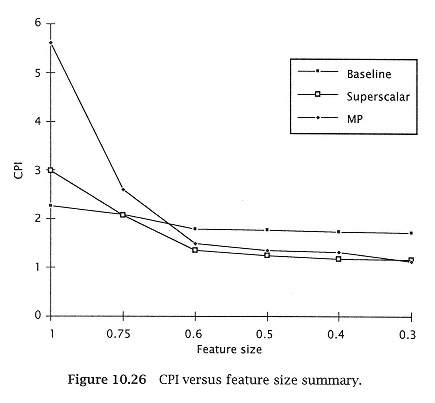
Figure 10.26
CPI versus feature size summary. |
|
|
|
|
|
|
|
|
different story. The multiprocessor implementation has a higher demand for bandwidth, and it is at a disadvantage due to the requirement for split I-cache. The CPI of the two implementations is roughly equalized at 0.3m. The slow decrease of CPI after 0.6m points out the fact that architects should consider other architectures at this point, such as higher-number-issue superscalar or higher multiprocessor implementations. However, steps must be taken to provide memory bandwidth so that the memory bus does not become the limiting factor. |
|
|
|
|
|
|
|
|
Some observations can be made based on results in the previous section. Performance gain due to scaling of technology levels out for our three implementations at different points. For the baseline case, insignificant gains are achieved as one scales below 0.75m. For the superscalar and multiprocessor implementations, the reduction of gains occurs at 0.6m. This should gives designers a hint for the future. As technology scales to below 0.6m, architects need to explore higher-issue superscalars and more than two multiprocessors on a single chip. The benefits of larger on-chip caches decline as these caches reach 128K (total) and beyond. One alternative that should be considered is on-chip secondary cache. |
|
|
|
|
|
|
|
|
The biggest issue facing architects is the widening gap between processor speed and memory latency. Based on our analysis, only the CBWA and secondary cache implementations are feasible. A simple bus-based memory |
|
|
|
|
|