|
|
|
|
|
|
|
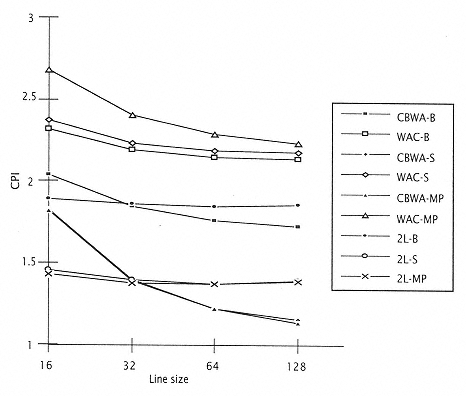
Figure 10.24
CPI/cache management policy summary for 0.30m. (Write policy-
Configuration. 2L indicates use of 2 levels on chip cache.) |
|
|
|
|
|
|
|
|
initial access time cannot be amortized, as in the case of line accesses. |
|
|
|
|
|
|
|
|
Figure 10.24 shows the same analysis for the 0.3m implementation. In this case, the best performance is multiprocessor with CBWA. This is a reversal from the 0.75m implementation, where the multiprocessor generally performed the worst. This graph does not include the WTNWA cases, since we have concluded that those are not feasible implementations. However, the secondary cache implementations are shown. Again, the question is, why does the secondary cache perform worse than the CBWA implementation at larger line sizes? As described earlier, this is due to the simple buffer implementation associated with the secondary cache. |
|
|
|
|
|
|
|
|
The main difference between the 0.3m and the 0.75m implementations is that the first-level cache is now sufficiently large to supply the bandwidth demands of the multiprocessor implementation. There is also much less degradation of CPI due to bus saturation (except in the case of WTNWA implementation). |
|
|
|
|
|
|
|
|
Multiprocessor Bus Contention |
|
|
|
|
|
|
|
|
The data in Figure 10.25 show the effect of bus contention in a multiprocessor system. The data presented are based on the following configuration: |
|
|
|
|
|