|
|
|
|
|
|
|
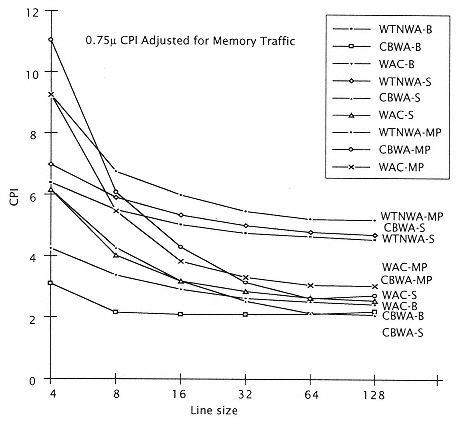
Figure 10.23
CPI/cache management policy summary for 0.75m. (Write policy-
Configuration: B = Baseline, S = Superscalar, MP = Multiprocessor.) |
|
|
|
|
|
|
|
|
In order to prevent the bus from becoming the system bottleneck, we can pick either the CBWA or the implementation with secondary cache. The total offered occupancy has to be kept below the maximum achievable occupancy. As we decrease the feature size, the situation is improved because larger caches reduce the bus traffic. |
|
|
|
|
|
|
|
|
The CPI models that we used previously assumed a ''perfect write buffer." These models for CPI are valid as long as bus occupancy is kept below one and a sufficiently large write buffer exists. However, when bus occupancy is above one, the bus saturates and we must consider total traffic and degrade CPI accordingly. Figure 10.23 shows the final CPI for the 0.75m implementations with bus traffic taken into account when necessary. |
|
|
|
|
|
|
|
|
Many useful conclusions can be drawn from Figure 10.23. The best-performing configurations are the superscalar and the baseline implementation with CBWA cache at a line size of 128 bytes. The fact that the baseline implementation comes out relatively even with the superscalar can be attributed to its larger cache and smaller need for bandwidth. Another interesting point is that the worst-performing implementations are all WTNWA, with WTNWA-MP being the worst. It is also notable that increasing the line size has less beneficial effect on WTNWA than on the other implementations. This is due to the fact that most of its traffic is word writes and the |
|
|
|
|
|