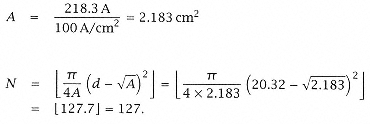|
|
|
| Table 10.7 Memory system delays. | | Miss Penalty | | | | Cache | | | | TLB | | | | Total Memory | | |
|
|
| Table 10.8 Processor system instruction cycle summary. |
| | Delay Source | | | | Instruction | | | | Pipeline | | | | Memory | | | | Total | | |
|
|
|
|
|
|
the reduced-scale and super-pipelined processorsis now easy to determine. First, using the Poisson model, we get a yield of: |
|
|
|
|
|
|
|
|
The 8-inch wafer gives a total die count of: |
|
|
|
|
|
|
|
|
Since there is an 11.3% yield, we get a total of 127 ´ 0.113 = 14.4 average good dies per wafer. The cost per chip is thus the packaging cost for a chip plus the net cost per die, or |
|
|
|
|
|
|
|
|
for the Baseline Mark I processor. Similarly, for the reduced-scale and super-pipelined processers, respectively, we get yields of 10.3% and 9.5%, areas of 2.269 cm and 2.359 cm, wafer counts of 122 and 117, average good dies per wafer of 12.6 and 11.1, and costs per chip of $496.8 and $550.5. Thus, the reduced-scale processor costs $49.6 (11.1%) more, and the superpipelined processor $103.3 (23.1%) more, than the original processor. |
|
|
|
|
|