|
|
|
|
|
|
|
found in Figure 5.46 and is 0.65%. The not-in-TLB penalty is found similarly to the cache miss penalty and is 20 cycles ´0.0102% = 0.204 cycles. |
|
|
|
|
|
|
|
|
With the reduced-scale processor version, the original processor area of 174.6 A is effectively increased to 232.8Athis adjustment takes into account the reduction to three-quarter scale and allows all calculations to be made using the nominal full-scale values. All the components on the chip (besides the TLB and cache and their overheads) occupy 71.85 A (16.1 + 37.8 + 41 - 6 - 14.05 - 3). This leaves us with 160.95 A (232.8 - 71.85) for the cache, TLB, and their overhead. This area is not large enough to permit doubling the caches and the TLBs. So we will consider doubling the I-cache to 32KB while leaving the D-cache at 8KB. Since we have doubled the I-cache, we also double the TLB associated with it. The 32-KB I-cache and the 8-KB D-cache occupy 132.8 A. Their overhead constitutes an additional 23.8A (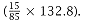 ). The TLBs now occupy 9A (6 + 3), while their overhead is 4.5 A. So the new cache + TLB configuration consists of 170.1 A (132.8 + 23.8 + 9 + 4.5). Thus, the total processor area of the reduced-scale processor is now 241.95 (170.1 + 71.85). When scaled back down, this implies a total actual area of 181.5 A. Including the 20% die overhead area, this gives a total die area of 226.9A, which still fits in the 230 A die originally specified for the Mark I Baseline processor. ). The TLBs now occupy 9A (6 + 3), while their overhead is 4.5 A. So the new cache + TLB configuration consists of 170.1 A (132.8 + 23.8 + 9 + 4.5). Thus, the total processor area of the reduced-scale processor is now 241.95 (170.1 + 71.85). When scaled back down, this implies a total actual area of 181.5 A. Including the 20% die overhead area, this gives a total die area of 226.9A, which still fits in the 230 A die originally specified for the Mark I Baseline processor. |
|
|
|
|
|
|
|
|
By redoing the calculations for the enlarged I-cache (32 KB), we find that it has a DTMR of 0.03 (Figure 5.30). The miss rate is now reevaluated with an fmapping of 1.04 (Figure 5.14) and an fsystem of 1.75 (Figure 5.22). It is found to be 0.0546, or 5.46%. The effective miss rate for both the I-cache and the D-cache is 13.2%, and the miss penalty is 0.66 cycles. The not-in-TLB rate for the D-cache (128 entries) is 0.65%, while the not-in-TLB rate for the I-cache (256 entries) is 0.39%. This yields an effective not-in-TLB rate of 0.76% ((1)(0.39%) + (0.235 + 0.33)(0.65%))hence, a miss penalty of 0.151 cycles. |
|
|
|
|
|
|
|
|
The super-pipelined processor uses the same basic configuration as the original Mark I unit, but includes an additional 10% pipeline latch overhead that affects the total processor area but not the die overhead. Thus, we get an increase of 17.5 A over the original design for a total processor area of 218.3A + 17.5A = 235.8A. Note that this makes both processors essentially the same as far as area considerations go.6 |
|
|
|
|
|
|
|
|
Since the super-scalar cache is the same as the cache in the original Mark I processor, it has a 16.8% miss rate and thus a 0.84 cycle miss penalty. The TLB is also the same as the TLB in the Mark I processor, and it has an effective 1.02% not-in-TLB rate with a .204 cycle not-in-TLB penalty. |
|
|
|
|
|
|
|
|
The memory results are summarized in Table 10.7, and the overall processor results are in Table 10.8. |
|
|
|
|
|
|
|
|
10.1.6 Cost-Performance Analysis |
|
|
|
|
|
|
|
|
We now have all the information from which to compute the actual cost and performance for these two processors. |
|
|
|
|
|
|
|
|
The fabrication cost of all three processorsthe original Mark I as well as |
|
|
|
 |
|
|
|
|
6There will be subtle differences between final chip costs due to variations in die production and yields, as is seen in section 10.1.6. |
|
|
|
|
|