|
|
 |
|
|
|
|
- Conditional case |
|
|
|
|
|
|
|
|
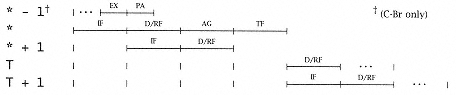
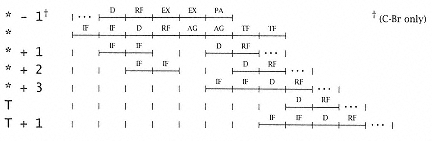
There is a 0-cycle delay for in-line, two half-cycle delays for target, four unused in-line instructions fetched on branch to target, and no unused target instructions fetched on continue in-line. The unused in-line instructions decrease to two as the condition dependency distance increases. This delay requires weighting according to Table 3.20, analogous to EX-EX interlock penalties, and so would be effectively reduced to 2.952 unused in-line instructions instead of the (more conservative) 4, from simply analyzing the worst-case static pipeline. |
|
|
|
|
|
|
|
|
For the reduced-scale version of the processor: |
|
|
|
|
|
|
|
|
- Unconditional case |
|
|
|
|
|
|
|
|
There is a 2-cycle delay, and one unused in-line instruction is fetched. Remember, there is no in-line case for an unconditional branch! |
|
|
|
|
|
|
|
|
- Conditional case |
|
|
|
|
|
|
|
|
There is a 0-cycle delay for in-line, a 2-cycle delay for target, one unused in-line instruction fetched on branch to target, and no unused target instructions fetched on continue in-line. |
|
|
|
|
|
|
|
|
For the super-pipelined version of the processor: |
|
|
|
|
|
|
|
|
- Unconditional case |
|
|
|
|
|
|
|
|
There is a 2-half-cycle delay for target and one unused in-line instruction fetched. Remember, there is no in-line case for an unconditional branch! |
|
|
|
|
|
|
|
|
24 ´ 0.40297 + 3 ´ 0.147 + 2 ´ (1.0 - (0.40297 + 0.147)) = 2.95. |
|
|
|
|
|