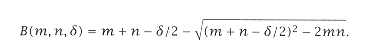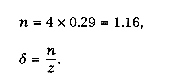|
|
 |
|
|
|
|
5 ´ 1.3 ´ 1.5 = 9.75 transactions per 100 instructions |
|
|
|
|
|
|
|
|
10.26 instructions per transaction. |
|
|
|
|
|
|
|
|
This slows down the processor from operating at 7.73 MIPS (no contention) to 7.27 MIPS. |
|
|
|
|
|
|
|
|
(b) Shared-bus multiprocessors without bus contention and with memory contention |
|
|
|
|
|
|
|
|
Now suppose each processor has its own bus (ideal bus), and the memory system has two independent modules each capable of a line access. They are interleaved on low-order line address, and any single module is busy for Tline access for each line access (i.e., page mode). |
|
|
|
|
|
|
|
|
We now use the d-binomial model from chapter 6 to compute the memory performance: |
|
|
|
|
|
|
|
|
Now m = 2 and we must find n and d. |
|
|
|
|
|
|
|
|
We compute n as the expected number of requests during Tline access. Each processor makes: |
|
|
|
|
|
|
|
|
5.85 references ´ 0.05 misses/reference |
|
|
|
|
|
|
|
|
= 0.29 miss requests/line access. |
|
|
|
|
|
|
|
|
Therefore, for four processors: |
|
|
|
|
|
|
|
|
Since we have three request sources each cycle (IF, DF, DS) and three cycles per memory busy time (line access, in this case), we have z = 3 ´ 3 ´ 4 (processors) = 36. So |
|
|
|
|
|
|
|
|
Now, using the d-binomial equation, we compute: |
|
|
|
|
|
|
|
|
B(m = 2, n = 1.16, d = 0.03) = 0.85 |
|
|
|
|
|