|
|
|
|
|
|
|
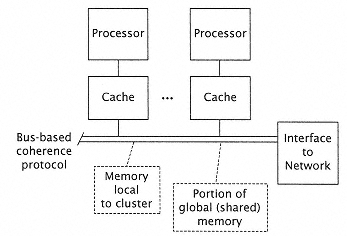
Figure 8.26
Typical processor-memory cluster. |
|
|
|
|
|
|
|
|
The processor is slowed down due to this contention. There are (1.5´1.3´5) = 9.75 transactions each 100 instructions, so there are 100/9.75 = 10.26 instructions between transactions, and each transaction takes 300 nsec. |
|
|
|
|
|
|
|
|
So, the processor's effective execution rate is slowed down by: |
|
|
|
|
|
|
|
|
and the effective processor execution rate is: |
|
|
|
 |
|
|
|
|
0.93 ´ 7.73 MIPS = 7.19 MIPS. |
|
|
|
|
|
|
|
|
Note that in this case, the bus or the memory as defined would equally limit processor performance. |
|
|
|
|
|
|
|
|
8.10 Scalable Multiprocessors |
|
|
|
|
|
|
|
|
Shared bus configurations of multiprocessors are obviously limited by bus bandwidth. At some point, the traffic required by the processors to retain a coherent picture of the memory state saturates the bus and at that point adding additional processors into such a system provides no net improvement in performance. To extend performance beyond this point requires a high bandwidth network and some mechanism to ensure memory coherency across the network. Suppose we consider the shared bus multiprocessor as a processor cluster (Figure 8.26). |
|
|
|
|
|
|
|
|
Figure 8.27 shows a system description of the scalable multiprocessor. Multiprocessor systems that consist of multiple clusters connected through a general interconnect network are the basis for implementing large-scale shared memory multiprocessors. If we can find a technique for facilitating a coherency protocol across an arbitrarily large number of clusters, we call that system a scalable shared memory multiprocessor. As the difficulty in |
|
|
|
|
|