|
|
|
|
|
|
|
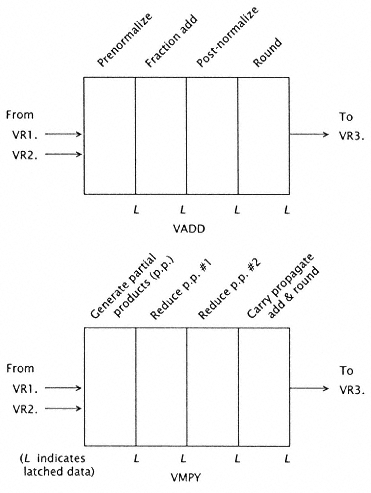
Figure 7.5
Two vector arithmetic units, each partitioned into four
pipeline stages. Results are latched at each latch point(L). |
|
|
|
|
|
|
|
|
vector transaction overlapped with subsequent instruction operations (see Figure 7.6), depending on data paths. Vector loads must complete before they can be used (Figure 7.7), since otherwise the processor would have to recognize when operands are delayed in the memory system. |
|
|
|
|
|
|
|
|
The ability of the processor to concurrently execute multiple (independent) vector instructions is also limited by the number of vector register ports and vector execution units. Each concurrent vector load or store requires a vector register port; vector ALU operations require multiple ports. Notice that necessary loop control present in scalar code is absent in the vector code. |
|
|
|
|
|
|
|
|
While it is not employed in the current generation of vector processors, it is possible to use a technique described in chapter 2anticipatory cycle techniquesto further enhance the performance of the vector processor. It may be possible to execute operands using wave pipelining at two to three times the ordinary cycle rate of the system. Vector operations are rather |
|
|
|
|
|