|
|
|
|
|
|
|
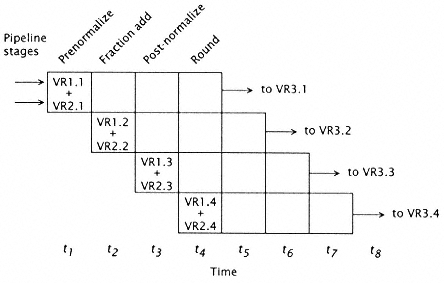
Figure 7.4
Approximate timing for a sample 4-stage functional pipeline. |
|
|
|
|
|
|
|
|
minimum we would expect to see the following functional units for floatingpoint: |
|
|
|
|
|
|
|
|
Logical operations, including compare. |
|
|
|
|
|
|
|
|
Usually there are separate and independent functional units to manage the load/store function. These functional units are also segmented (pipelined) to support the highest possible execution rate. Since the whole purpose of introducing the vector vocabulary is to manage operations over a vector of operands, it is assumed that there is a relatively large number of operands per operation. Thus, once the operation is begun, it can continue at the cycle rate of the system. Figures 7.4 and 7.5 show the approximate timing for a sample 4-stage functional pipeline. Figure 7.4 shows a vector add sequence of elements as vector elements pass through various stages in the adder. The sum of the first elements of VR1 and VR2 (labeled VR1.1 and VR2.1) are stored in VR3 (actually, VR3.1) after the fourth adder stage. |
|
|
|
|
|
|
|
|
Segmentation, or pipelining, of the functional units is more important for vector functional units than for scalar functional units, where latency is of primary importance. If the ordinary scalar floating-point hardware can be pipelined at the clock rate of the system (the decode rate), then no further pipelining need be done. The advantage of vector processing is that fewer instructions are required to execute the vector operations. A single (over-lapped) vector load places the information into the vector registers. The vector operation executes at the clock rate of the system (one cycle per executed operand), and an overlapped vector store operation completes the |
|
|
|
|
|