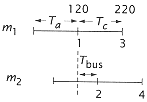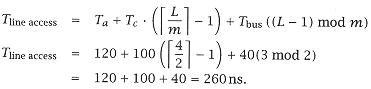|
|
|
|
|
|
|
Figure 6.28
Accessing for m = 2, L = 4. |
|
|
|
|
|
|
|
|
We begin by finding Tline access Since |
|
|
|
 |
|
|
|
|
m Tbus = 2 40 = 80 ns, |
|
|
|
|
|
|
|
|
and therefore Tc > m Tbus. |
|
|
|
|
|
|
|
|
Thus, the average miss delay including the effects of writes is |
|
|
|
|
|
|
|
|
Tm.miss = (1 + w) Tline access = 1.5(260) = 390 ns. |
|
|
|
|
|
|
|
|
For our example, Tinterference is zerothere is no contention for the memory. What has happened is that Tbusy = Tm.miss - Tc.miss = 0. |
|
|
|
|
|
|
|
|
The processor does not create any contention for memory, since it waits until memory is free before (potentially) making another request. |
|
|
|
|
|
|
|
|
Now we can compute the effect of the cache on the processor in cycles/processor cycle. Assume the processor makes a reference to this cache every cycle (40 ns). The effect of this cache on processor performance is |
|
|
|
|
|
|
|
|
(b) Assume now we have a CBWA cache with write (dirty line) buffer; again wraparound load is not used (ignore I/O). As before, Tline access = 260 nsec and Tm.miss = 390 nsec. Now Tc.miss = 260 nsec and Tbusy = Tm.miss - Tc.miss = 130 nsec. |
|
|
|
|
|