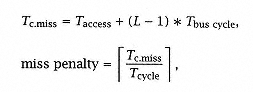|
|
|
|
|
|
|
where tcycle is the processor cycle time. CPI is the computed cycles per instruction for the processor, including pipeline breaks. Miss penalty is the cache miss penalty in cycles; in other words, the number of cycles the processor is idled by a miss awaiting data from memory. |
|
|
|
|
|
|
|
|
In our performance model, suppose the CPU cycle is determined by cache access time. Large cache sizes or higher degrees of associativity give smaller miss rates but may result in larger CPU cycle times. For large cache sizes, more performance improvement can be achieved by decreasing CPU cycle time than by doubling the cache size. For small caches, the opposite is true [220]. |
|
|
|
|
|
|
|
|
Consider this in the context of the processor used in study 4.1. |
|
|
|
|
|
|
|
|
This study demonstrates how our data (i.e., DTMR, etc.) can be incorporated with system parameters to evaluate the overall performance. We show part of the design space and illustrate some performance tradeoffs possibly encountered in cache design [237, 130]. |
|
|
|
|
|
|
|
|
Set associativity: two-way associative. |
|
|
|
|
|
|
|
|
System activities included. |
|
|
|
|
| | | | | | | | | |
|
|
|
|
8 bytes (width of bus in bytes). |
|
|
|
|
|
|
|
|
|
|
In this study, we are interested in machine speed (i.e., MIPS rate). The performance measure is CPU time per instruction (CTPI), defined earlier. |
|
|
|
|
|
|
|
|
We use the following equations to compute CTPI: |
|
|
|
|
|
|
|
|
where L is the number of physical words in a line (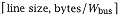 ), Tbus cycle is the bus transfer time for a physical word, and Wbus is the size of the physical word fetched on each bus cycle (in bytes). We assume that Tbus cycle is the same as the processor cycle (Tcycle). Taccess is the access time for a word in memory. ), Tbus cycle is the bus transfer time for a physical word, and Wbus is the size of the physical word fetched on each bus cycle (in bytes). We assume that Tbus cycle is the same as the processor cycle (Tcycle). Taccess is the access time for a word in memory. |
|
|
|
|
|