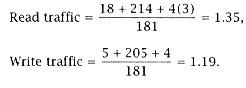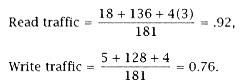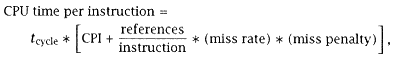|
|
|
|
|
|
|
integer, we compute traffic for each instruction type (only decimal arithmetic takes two source operands). This is tabulated in Table 5.8. |
|
|
|
|
|
|
|
|
Combining this with frequency data, we can compute the read and write traffic per instruction (P = 4, see Table 5.7): |
|
|
|
 |
|
|
|
|
Total reads per 100 HLL ops |
|
|
|
|
|
|
|
|
= Integer reads (Table 3.16) + Byte reads (Table 5.8) + LDM's, |
|
|
|
|
|
|
|
|
and then continue as above: |
|
|
|
|
|
|
|
|
As with the scientific environment, we treat the number of integer fetches and stores as invariant across architectures. (Assume all architectures have the same register set design.) These numbers (54 fetches/100 HLL ops and 16 stores/100 HLL ops) are more readily available from L/S data, as that architecture does not allow a data fetch as part of an arithmetic operation. The LDM and STM activity is also the same for all architectures. |
|
|
|
|
|
|
|
|
5.15 Technology-Dependent Cache Design Considerations |
|
|
|
|
|
|
|
|
There are several other effects that the cache may have on the overall effectiveness of the processor design. For example: |
|
|
|
|
|
|
|
|
1. The cache may determine the CPU cycle time; the cycle time is then a function of cache size. |
|
|
|
|
|
|
|
|
2. The cache determines the memory access time. |
|
|
|
|
|
|
|
|
3. The cache determines the bus busy time, and through this the effective memory access time. |
|
|
|
|
|
|
|
|
All of these may directly affect processor performance. |
|
|
|
|
|
|
|
|
So far, our model of CPU performance is: |
|
|
|
|
|