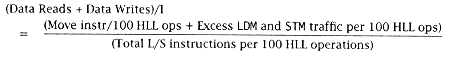|
|
|
|
|
|
|
and the total I-traffic per I is |
|
|
|
|
|
|
|
|
The 0.73 I-reference per I was computed without regard to the I-cache design. Note that it appears that two references must be simultaneously handled by the I-cache during TIF fetch. If, as is common, the cache is limited to one access per cycle, the fetch of * + 5 and subsequent words are delayed by one cyclethus, only six excess references are made. However, only 3.0 references are actually made to the cache to fetch the additional instructions, so this accessing is completed before the TIF is initiated. |
|
|
|
|
|
|
|
|
Computation of data traffic is relatively straightforward. First, we determine the number of instructions that use a data operand from memory and then distinguish between reads and writes. In the scientific environment for L/S architectures, we can use Tables 3.4 and 3.15. Note that there are no memory to memory instructions; thus: |
|
|
|
|
|
|
|
|
We find the LD and ST instructions breakdown per 100 HLL ops in Table 3.15 and the number (200) of L/S instructions per 100 HLL ops in Table 3.4. |
|
|
|
|
|
|
|
|
Some instructions take more than one operand (load multiple, store multiple, and the memory to memory instructions). For the load and store multiple instructions we need to know the average number of registers that are involved in the operation (section 3.3.1). |
|
|
|
|
|