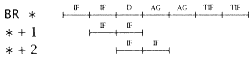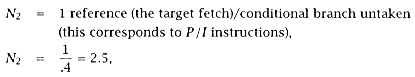|
|
|
|
|
|
|
may not create a reference, however. Assuming the path between cache and processor is 8B, the average instruction is considerably smaller, and multiple instructions may be brought into an instruction buffer by a single reference. |
|
|
|
|
|
|
|
|
In our case, with an 8B data path between cache and processor, we can estimate the average instruction size from Table 3.2, assuming the scientific environment average size is 3.2B. |
|
|
|
|
|
|
|
|
Thus, each instruction creates 3.2B/8 = 0.40 I references/instruction. To the preceding we must add the extra traffic created by branch instructions, which depends on the branch prediction strategy. |
|
|
|
|
|
|
|
|
As in study 4.3, we fetch one word of target, otherwise fetch in-line, and conditional branches are taken 50% of the time. |
|
|
|
|
|
|
|
|
Unconditional branch (*) excess traffic (the frequency of unconditional branch is 0.05, from study 4.3): |
|
|
|
|
|
|
|
|
Before the IF for *+3, the branch at * has been decoded and in-line fetching ceases, N1 = 2. So, the excess traffic for unconditional branches is: |
|
|
|
 |
|
|
|
|
.05 [2I/P] = 0.05(0.8) = 0.04 excess references. |
|
|
|
|
|
|
|
|
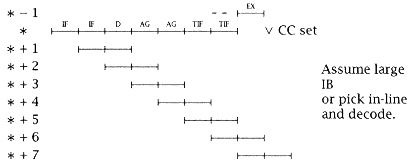
Conditional branch (*) with target taken (from study 4.3, the frequency of conditional branch is 15%): |
|
|
|
|
|
|
|
|
Here, seven in-line instructions are fetched, so N3 = 7 and for the conditional branch (*) with in-line taken: |
|
|
|
|
|
|
|
|
since only the target fetch is in excess of instructions used. |
|
|
|
|
|
|
|
|
Now we can compute the excess BC traffic: |
|
|
|
|
|
|
|
|
0.15[.5(7)(.4) + .5(2.5)(.4)] = 0.285, |
|
|
|
|
|