|
|
|
|
|
|
|
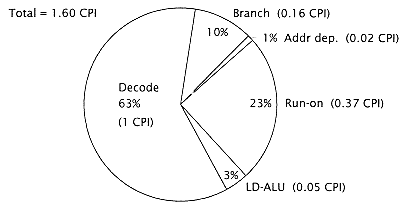
Figure 4.32
Baseline processor performance (without cache). |
|
|
|
|
|
|
|
|
where wi is the probability of a particular run-on instruction, corresponding to its frequency of occurrence. For our instruction profile: |
|
|
|
 |
|
|
|
|
Run-on delay = 0.37 CPI delay. |
|
|
|
|
|
|
|
|
Our processor performance is now determined as: |
|
|
|
|
| | |
|
|
|
|
1(decoder) + 0.16(branch delay) + 0.05(LD-ALU) +0.02(addr dep. delay) + 0.37(run-on delay) |
|
|
|
| | | |
|
|
|
|
|
|
Suppose we are now pressured by our marketing organization to show better performance. What can we (easily) do? Overall, our baseline processor without modification has .67 excess CPI per instruction. Of these, 0.16 are due to branches that can be reduced with a minimum of additional area: |
|
|
|
|
|
|
|
|
1. We can overlap the branch address generation with branch decode by using a separate branch address adder. So long as the branch target lies within the current page, it requires no translation. This has the effect of changing the branch timing templates to the following: |
|
|
|
|
|
|
|
|
This halves the branch penalty from two cycles to one, and reduces the overall effects of branch from .16 excess CPI to about 0.08. |
|
|
|
|
|
|
|
|
2. We can also use a small instruction buffer. Suppose we have a 64-bit path from high cache to the instruction buffer. This will not affect the overall timing or delays due to branches, but it will later reduce the possibility of contention at the cache, which at this moment we are not considering. |
|
|
|
|
|
|
|
|
While there is not much to be (easily) done about data dependencies, we can improve run-on delay simply by changing the application (benchmark) base. Of the run-on delay (.37 cycles per instruction), 0.29 excess CPI is due |
|
|
|
|
|