|
|
|
|
|
|
|
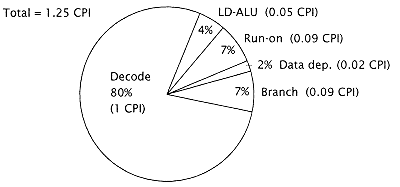
Figure 4.33
Improved baseline processor with branch adder running
"integer" benchmarks (no cache misses). |
|
|
|
|
|
|
|
|
to floating-point instructions when running non-floating point programs. Suppose that in these workstation (or benchmark) applications the instruction profile remains unchanged, except that floating-point instructions are absent. This eliminates 12% of the instructions (we assume floating-point LD and ST are replaced with integer LD and STs). The remaining branch, run-on, and data dependencies are now slightly more frequent. We estimate this effect as amplifying these non-floating delays by 1/(1-.12) = 1.136, so that now we have: |
|
|
|
|
| | |
|
|
|
|
Integer run-on delay ´ 1.136 |
|
|
|
| | | |
|
|
|
|
(14 ´ 0.004 + 2 ´ 0.012) ´ 1.136 |
|
|
|
| | | | | | | | | |
|
|
|
|
|
|
The new performance is 1.32 CPI. This is shown in Figure 4.33. |
|
|
|
|
|
|
|
|
Of course, all of this ignores delays in the memory hierarchy, which we discuss in the next chapter. |
|
|
|
|
|
|
|
|
Pipelined processors have become the implementation of choice for almost all machines from mainframes to microprocessors. High-density VLSI logic technology, coupled with high-density memory, has made possible this movement to increasingly complex processor implementations. |
|
|
|
|
|
|
|
|
In modeling the performance of pipelined processors, we generally allocate a basic quantum of time for each instruction and then add to that the expected delays due to dependencies that arise in code execution. These dependencies usually arise from branches, dependent data, or limited execution resources. For each type of dependency, there are implementation strategies that mitigate the effect of the dependency. Implementing branch prediction strategies, for example, mitigates the effect of branch delays. |
|
|
|
|
|