|
|
|
|
|
|
|
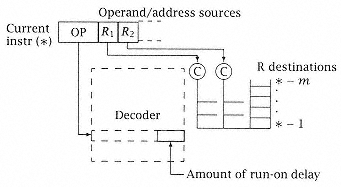
The effect of the interlocks (Figure 4.27) is that for each instruction as it is decoded, its source registers (for operands or addresses) must be compared against the destination registers of previously issued but uncompleted instructions to determine dependencies. The opcode itself usually establishes the number of EX cycles required. If this exceeds that number specified by the timing template, subsequent instructions must be delayed by that amount to preserve in-order execution. |
|
|
|
|
|
|
|
|
The store interlocks (E) perform the same function as the data interlocks for storage addresses rather than registers. On store instructions, the address generated must be sent to the store interlocks so that subsequent reads either from the AG (data reads) or the IB (instruction reads) can be compared with pending stores and dependencies detected. |
|
|
|
|
|
|
|
|
Bypassing (sometimes called forwarding) is accomplished by a data path that routes a value from a source (usually an ALU) to a user (perhaps also the ALU), bypassing a designated destination register. Especially for static pipelines, this allows the value produced to be used at an earlier stage in the pipeline than would otherwise be possible. Bypassing can also be used at the instruction level, where instruction dependencies arise from the use of a designated register rather than the value in that register. Instruction level bypassing is discussed later in this chapter. |
|
|
|
|
|
|
|
|
At the pipeline level, the bypass data path routes results from ALU (EX) or from storage (as in an LD instruction, DF) to either the address generate (AG) unit or to the ALU (EX). Thus, in a timing template such as: |
|
|
|
|
|
|
|
|
a subsequent instruction can only use the register after PA without bypassing. With bypassing, the result could be available after the EX (or after the DF in case of an LD instruction, as shown in examples 4.2 and 4.3). |
|
|
|
|
|