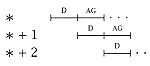|
|
|
|
|
|
|
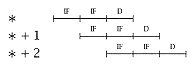
The instruction buffer ought to be transparent to instruction execution. If an instruction is in the I-buffer, we assume that it can be accessed and decoded in one decode cycle (D). Depending on the type of analysis we are doing, we may show a buffered instruction execution sequence as: |
|
|
|
|
|
|
|
|
without indicating the IF, or we may show it as: |
|
|
|
|
|
|
|
|
to indicate that the IF occurred at some time prior to the corresponding decode (D). The reader should note that in the presence of a buffer, the IF may have occurred several cycles earlier than indicated. Also, while it appears that a single IF occurs per instruction, the IF may actually fetch several instructions at once. We consider these possibilities later in this chapter. |
|
|
|
|
|
|
|
|
Buffers may be designed for a mean request rate or for a maximum request rate. In the former case, we estimate the expected number of requests and then trade off buffer size against the probability of an overflow. Overflows per se (where an action is lost) do not happen in internal CPU buffers, but an "overflow" conditionfull buffer and a new requestwill force the processor to slow down to bring the buffer entries down below buffer capacity. Thus, each time an "overflow" condition occurs, the processor pipeline stalls to allow the overflowed buffer to access memory (or other resource). The store buffer is usually designed for a mean request rate. |
|
|
|
|
|
|
|
|
For request sources that dominate performance, such as in-line instruction requests, we design for the maximum request rate. We ensure that the buffer size is sufficient to match the processor request rate with the cache service rate. A properly sized buffer allows the processor to continue accessing instructions at its maximum rate without the instruction buffer running out of instructions. |
|
|
|
|
|
|
|
|
4.4.4 Designing a Buffer for a Mean Request Rate |
|
|
|
|
|
|
|
|
Suppose we have determined the mean request rate for a particular source. How large should we make the buffer to hold these requests? Assume we know Q, the mean number of requests present in a cycle. For internal processor buffers, each source can make a maximum of one request per cycle, but these requests can cluster and appear to a buffer accessing a slower memory as multiple concurrent requests. Now we can use the well-known Chebyshev's Inequality or a variation thereof. |
|
|
|
|
|