|
|
|
|
|
|
|
2. I-buffer (target fetch). |
|
|
|
|
|
|
|
|
3. I-buffer (in-line fetch). |
|
|
|
|
|
|
|
|
4. Data write (unless the store buffer is full). |
|
|
|
|
|
|
|
|
Data reads are given priority, assuming that an ample I-buffer is part of the design. (See section 4.4.2.) For data writes, priority is given to stores if the store buffer is full; otherwise, priority is given to reads (of all types). |
|
|
|
|
|
|
|
|
Contention for cache access is frequently a concern for processor designers, and split cache designs (I and D, see chapter 5) are a popular method to double the available cache accessing bandwidth. For many register set architectures with a well-designed I-buffer and 8-byte access paths, cache contention at a single integrated cache should not be a serious source of contention, so long as the cache can accommodate a request each cycle. (See study 5.4.) |
|
|
|
|
|
|
|
|
4.4.2 Accounting for the Effect of Buffers in a Pipelined System |
|
|
|
|
|
|
|
|
Buffers, however they are organized, change the way our instruction timing templates are used. The buffer decouples the time at which an event occurs from the time at which the input data is used. |
|
|
|
|
|
|
|
|
For example, so far we have shown processors without explicit I-buffers. Thus, actions proceed: |
|
|
|
|
|
|
|
|
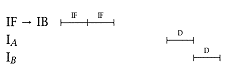
Suppose now that * is a branch (BC) and * + 1 has its decode delayed by three cycles: |
|
|
|
|
|
|
|
|
The IF for * + 1 occurs before * is known to be a branch. Presumably, there is someplace to keep the result of the IF (a minimal one-entry buffer) so that the decode of * + 1 can proceed when the branch decision is determined (assuming the in-line path is selected). Note that in this case the IF completed three cycles before its decode began. |
|
|
|
|
|
|
|
|
Larger buffers generalize the preceding situation. A single IF may fetch two instructions (A and B) into the instruction buffer to be used several cycles later, and we might have: |
|
|
|
|
|