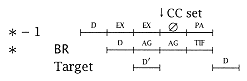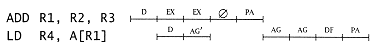|
|
|
|
|
|
|
pipeline (as assumed throughout this chapter), the instruction goes through just those stages required for completion. Using a dynamic pipeline may or may not affect the various pipeline delays, since in-order decode and especially in-order execute (or putaway) restrict any advantage. |
|
|
|
|
|
|
|
|
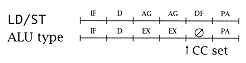
We compare these two approaches for a L/S processor with decode on successive cycles. First, assume a static pipelined processor with the following timing templates: |
|
|
|
|
|
|
|
|
Here, an ALU operation takes two EX cycles, then a dummy cycle (Æ), and finally a PA (CC is set at the end of the last EX cycle). The load/store instruction uses the ALU for two AG cycles instead of EX. For a static pipeline, we would have the following branch delays: |
|
|
|
|
|
|
|
|
Thus, the delay is three cycles on unconditional branch (BR). The PA in * - 1 is delayed to ensure ordering of events within the timing template (Æ represents no action). Note that * - 1 and * end at the same time, but there is no out-of-order problem, since only the PA must be in order and only * - 1 uses PA. |
|
|
|
|
|
|
|
|
For BC, the situation is the same, but since the CC is set early, the in-line path can proceed with only one cycle of delay. Assume that 50% of the BC instructions go to the in-line and 50% go to the target instruction path (roughly following the Chapter 3 data). Then the BC delay is 0.5 * 3.0 cycles (for the target pathsee BR) plus 0.5 * 1.0 (for the in-line path decode, which occurs immediately after CC set), for a total of 2.0 cycles. |
|
|
|
|
|
|
|
|
For address dependency (assuming no bypassing), we might have: |
|
|
|
|
|
|
|
|
This has a 3-cycle delay. |
|
|
|
|
|
|
|
|
For the dynamic pipeline, we might have timing templates such as: |
|
|
|
|
|
|
|
|
Despite the more flexible pipeline, the BR and BC delays remain the same, since the CC is set at the same time in both pipelines and the target fetch time is the same. The situation with an address dependency is different, however: |
|
|
|
|
|