|
|
|
|
|
|
|
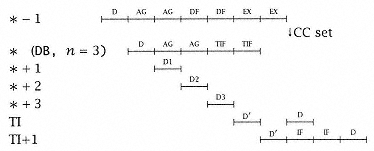
The performance includes only the effects of branch. The taken conditional DB case for n = 3 is shown as follows: |
|
|
|
|
|
|
|
|
There is a 3-cycle decode delay in TI + 1. |
|
|
|
|
|
|
|
|
The effectiveness of either approach depends on finding useful instructions that can be done in the delay slots. Current implementation data suggest that n > 1 [192] (i.e., more than one delay slot) may be of only marginal value. |
|
|
|
| |
|
|
|
|
There is no easy way around the branch delay penalty. The designer may avoid the penalty completely by creating a very simple processor with a long cycle and limited performance in the first place. |
|
|
|
| |
|
|
|
|
In modern microprocessors, the processor cycle time is decreasing at a faster rate than the memory cycle time, creating multiple cycle accesses to external storage, either cache or main memory. These trends tend to increase the number of cycles involved in instruction execution, and also increase the relative size of the branch penalty. |
|
|
|
| |
|
|
|
|
Even for microprocessors with on-chip cache, the relative size of these processors and size of their caches create a need for multiple cycle access to the cache, again promoting the long-term trend toward increased branch penalty. |
|
|
|
|
|
|
|
|
|
Study 4.5 Static and Dynamic Pipelines |
|
|
|
 |
|
|
|
|
Assumptions: |
|
|
|
|
|
|
|
|
In this study, we assume a L/S architecture with a simple basic timing allocation. A fast access to memory (IF or DF) of one cycle is assumed. This reduces branch penalties. We further assume that the processor guesses the in-line path on a conditional branch. |
|
|
|
|
|
|
|
|
Simple pipelined processors use a static pipeline, where an instruction must go through all stages of pipeline whether required or not. In a dynamic |
|
|
|
|
|