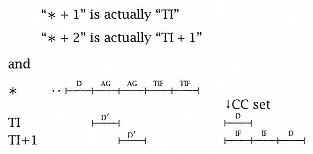|
|
|
|
|
|
|
where wi is the weight or frequency of the ith delay and di is the corresponding delay in cycles. Note that this is a simplifying (linear) assumption. Dubey [76] has developed a more accurate model, that is, corresponding more to complex models of overlapping delays (di). |
|
|
|
|
|
|
|
|
We now compute each delay. |
|
|
|
|
|
|
|
|
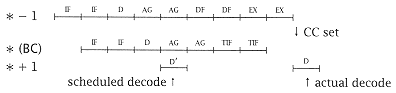
(i) Evaluate the conditional branch (BC) penalty: |
|
|
|
|
|
|
|
|
The conditional branch instruction tests the condition code (CC) set by a preceding instruction. While some instructions set the CC, some do notand the CC setting instruction could occur several instructions before the branch that tests the CC. The most frequent case is that the instruction that immediately precedes the branch sets the CC. For evaluation purposes, we assume that this is the case and, at * - 1, there is an arithmetic instruction with a basic timing template that sets the CC. If the condition specified in the branch on condition matches the CC, the branch is taken (or the branch succeeds). In this case, the next instruction following the branch is the target instruction (TI) whose location is determined by the branch instruction and is fetched by the branch instruction during TIF. Of course, if the condition specified by the BC is not met, instruction sequencing continues in-line. What should the processor do while awaiting the outcome of the branch? There may be a number of cycles available between the decoding of the branch and the setting of the condition code (in * - 1). The simplest strategy is for the processor to do nothing; simply await the outcome of the CC set and defer the decoding of the instruction following the BC until the CC is known. Both in-line and target paths can and normally would be fetched; the target path is fetched during the time allocated to a data fetch in an arithmetic instruction. This policy is simple to implement and minimizes the amount of excess memory traffic created by branch instructions. More complicated strategies that attempt to guess a particular path will occasionally be wrong and cause additional or excess instruction fetches from memory. |
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
In the preceding, the actual decode is 5 cycles late (i.e., a 5-cycle branch penalty). This is not the whole effect, however. Consider the timing of * + 2. If the path selected is in-line, and the branch fetch policy is to continue fetching in-line until the CC is set (one word of target is fetched at TIF), then the * + 2 penalty is 5 cycles; but if the target path is taken, then: |
|
|
|
|
|