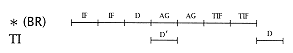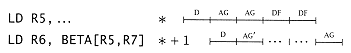|
|
|
|
|
|
|
In this case, TI + 1 decode is delayed 6 cycles. If the branch is equally likely to go in-line as it is to take the target (TI), then the effective penalty is 5.5 cycles. |
|
|
|
|
|
|
|
|
(ii) The effects of the unconditional branch (BR) can be similarly evaluated: |
|
|
|
|
|
|
|
|
For this case, the penalty is 4 cycles. |
|
|
|
|
|
|
|
|
Now, assuming the frequency of conditional branch is 15% and unconditional branch is 5%, we can compute the effect of branches on processor performance. |
|
|
|
|
| | |
|
|
|
|
1 (decode) + .15(5.5) + .05(4), |
|
|
|
| | | |
|
|
|
|
1 + 0.825 + 0.20 = 2.025. |
|
|
|
|
|
|
|
|
|
|
(iii) Consider the effect of address dependencies: |
|
|
|
 |
|
|
|
|
LD R5, ALPHA[R6,R7]
LD R6, BETA[R5,R7] |
|
|
|
|
|
|
|
|
This results in a 3-cycle penalty. Similarly, |
|
|
|
|
|
|
|
|
ADD R5, ALPHA[R6,R7]
LD R6, BETA[R5,R7] |
|
|
|
|
|
|
|
|
Assume a 3-cycle penalty occurs in 4% of the instruction executions and a 5-cycle penalty occurs 1.5% of the time. We now have performance: |
|
|
|
|
| | |
|
|
|
|
2.025 + 0.04(3) + 0.015(5), |
|
|
|
| | | | | | |
|
|
|