|
|
|
|
|
|
|
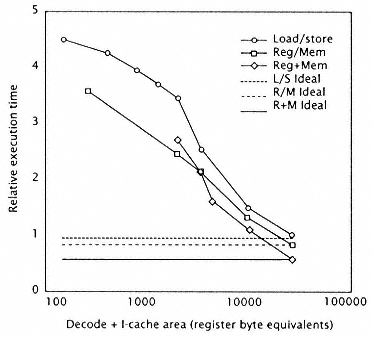
Figure 2.43
Execution time relative to L/S for three architectures with
different code densities with the same allocation of area
to decoder plus Icache. Figure assumes all architectures
ultimately achieve 1 cycle per instruction. |
|
|
|
|
|
|
|
|
of one cycle and a cache miss time of five cycles, we can compare the relative execution time of our three architectures. Using an ideal cache for each, we can plot the relative execution time vs. the available area for decoder plus Icache (Figure 2.43). Figure 2.43 then represents the relative execution time for the three architectures with different code densities, but with the same allocation of marginal area to the decoder plus the I-cache. When little or no additional area is available to the base processor, the best instruction set is the L/S instruction set, as it is the only instruction set that is realizable without significant implementation compromises. When a small additional area is available, the R/M instruction set prevails. Finally, assuming the cycle time remains constant, the R+M architecture provides the best performance by a small measure, as it executes the fewest instructions. If we model the base execution time as proportional to the number of instructions executed, then asymptotically the R+M machine would use only .6 of the execution time of the L/S machine, and the R/M machine would use only .9 of the execution time of the L/S machine. |
|
|
|
|
|
|
|
|
The preceding argument is more generally applicable than just to the comparison among our prototypical instruction sets. Given a base L/S architecture (or any other), any instruction encoding improvement that provides a 20% bandwidth reduction (no cache) would achieve performance improvement similar to that outlined in Figure 2.43. The cost (i.e., area required) of any such encoding improvement must be added to the I-cache area. |
|
|
|
|
|