|
|
|
|
|
|
|
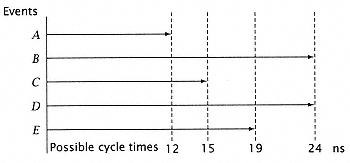
Figure 2.14
Where to put the cycle boundary. |
|
|
|
|
|
|
|
|
where tm is simply Dt - C, the time between clocks. There are two distinct overheads here; sC is the clocking overhead and it grows as s grows. The other overhead is: |
|
|
|
|
|
|
|
|
or the quantization overhead. Presumably, if tm were made small and s correspondingly large, then |
|
|
|
 |
|
|
|
|
sitm - ti® 0 for all i, |
|
|
|
|
|
|
|
|
where si is the smallest integer to make the above equal to or greater than zero. The overall effect of quantization is |
|
|
|
|
|
|
|
|
stm - T. |
|
|
|
|
|
|
|
|
In reducing tm to reduce quantization overhead, we increase s and hence increase the clocking overhead. There is a delicate balance between the two overheads, as illustrated in the following study. |
|
|
|
|
|
|
|
|
Study 2.2 Cycle partitioning |
|
|
|
|
|
|
|
|
Suppose a processor's instruction execution requires a sequence of five events (Figure 2.14) A, B, C, D, and E, with respective delays of: |
|
|
|
|
|