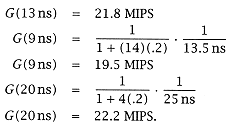|
|
|
|
|
|
|
Figure 2.13
Cycle time quantization. T is the total unquantized instruction
execution delay, sDt is the quantized instruction execution delay. |
|
|
|
 |
|
|
|
|
While the Tseg = 13 ns and 20 ns partitions give practically the same performance, the 20 ns is clearly to be preferred, since it is a less complex design with fewer pipeline stages. |
|
|
|
|
|
|
|
|
Generalizing the preceding, we compute Sopt, but use it only as a rough guideline in the partitioning process. It is also rather an "upper limit" for the number of segments, since the complexity (and cost) of additional pipeline segmentation makes such segmentation (beyond Sopt) impractical. The designer ought to consider several segment times in the range from T/Sopt through (at least) 2T/Sopt, observing (1) performance sensitivity and (2) resultant design complexity. The larger the number of segments, the more complex the design. |
|
|
|
|
|
|
|
|
Usually, larger functional units can be segmented into pipeline stages, but segmentation cannot occur across segments. This gives rise to a loss of performance due to cycle quantization. This is the time lost to fitting functional unit delays into fixed cycle times. In the previous example (study 2.1), we can combine I-decode and Address Generate into a cycle (12+9 = 21 ns), but we cannot combine an I-decode with (say) half of the AG. |
|
|
|
|
|
|
|
|
In general, in order to minimize instruction execution delay, one must minimize the time wasted due to cycle quantization and cycle overhead. That is, if the unit delay for the ith unit is ti and if the total unquantized instruction delay is T, then |
|
|
|
|
|
|
|
|
After clocking, execution occurs at the clock rate (Dt), and if instruction execution requires s cycles (or time sDt), then, ignoring k (as shown in |
|
|
|
|
|