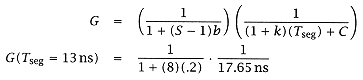< previous page
page_75
next page >
Page 75
2. Partition the actions into approximately
S
opt
segments.
We begin by partitioning the actions into possible segments (Figure 2.12(a)), using as a rough rule (not a maximum) the expected time per segment,
T
seg
= time per segment = 10.0 ns.
We label each stage with the principal action that occurs within it.
Note that some stages (e.g., 2 and 3) will not "fit" into the target
T
seg
= 10 ns, but they do not greatly exceed
T
seg
.
3. We now compute the total instruction execution time based on several trial cycle times.
In the preceding partition, the worst stage delay was 13 ns (stage 2), excluding clocking effects. So now let us use
T
seg
= 13 ns:
D
t
=
cycle time = max stage time + overheads
=
(1 +
k)T
seg
+
C
=
(13 ns)(1.05) + 4 = 17.65 ns
T
inst
=
(stages)(
D
t)
= (9)(17.65 ns)
T
inst
=
159 ns.
We could also try a minimum partition of (say)
T
seg
= 9 ns:
D
t
=
a stage time + overheads
=
9(1.05) + 4 = 13.5 ns
T
inst
=
(stages that fit in 9 ns)(
D
t)
+ (stages that do not fit) (2
D
t)
=
(3)(13.5) + (6)(2)(13.5)
T
inst
=
202.5 ns.
At the other extreme, if we tried a coarser partition such as
T
seg
= 20 ns, we would have Figure 2.12(b), which creates a cycle of:
D
t
= (20 ns)(1.05) + 4 = 25 ns
and a total instruction execution time of:
T
inst
= (5 stages)(25 ns/stage) = 125 ns.
4. We now compute the expected performance
G
in million instructions per second for each trial cycle used previously.
The performance for each partition can be computed:
< previous page
page_75
next page >