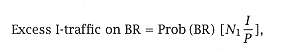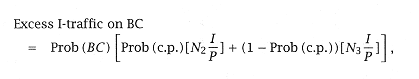|
|
|
|
|
|
|
With the additional branch adder, we save a cycle in cache access, since we have removed the conflict with ALU operations and branch target address computation (AG), which is generated during the decode stage. We opt to use the static prediction strategy, since the required hardware cost is small and the accuracy achieved is 60 to 70%. For unconditional branch, the added reference traffic is: |
|
|
|
|
|
|
|
|
where N1 is the number of in-line instructions fetched before the branch is decoded, and BR is the frequency of an unconditional branch. For our pipeline layout, N1 is one cycle. From study 4.11, the branch profile is: |
|
|
|
|
| BR | 2.6% | | BC | 10.4% with 54% to target |
|
|
|
|
|
|
The added reference traffic is: |
|
|
|
|
|
|
|
|
where N2 is the number of unused instructions fetched given a correct prediction, and N3 is the number of unused instructions fetched given an incorrect prediction. |
|
|
|
|
|
|
|
|
For our pipeline and branch prediction scheme, N2 = 0 and N3 = 1. The width of the I-buffer-I-cache interface is critical for high performance. The basic idea is that we must meet or exceed the maximum bandwidth requirements of the instruction issue logic. Decreasing the width results in higher reference traffic, leading to a greater number of misses and higher CPI. |
|
|
|
|
|
|
|
|
Before proceeding to cache design, another integral part of the memory hierarchy design deserves consideration. The aforementioned I-buffer provides the interface between the instruction execution stream and the storage providing the instructions, whereas the write buffer can serve a multitude of purposes: |
|
|
|
|
|
|
|
|
1. Since write traffic tends to be temporal, a write buffer can filter out some write traffic by eliminating identical write requests by updating the write buffer instead of writing directly to memory. |
|
|
|
|
|
|
|
|
2. Write buffer alleviates the latency differences between the processor and off-chip memory. The processor can write to the write buffer instead of waiting to gain ownership of the memory interface bus and completing the write to memory prior to processing more instructions. |
|
|
|
|
|