|
|
|
|
|
|
|
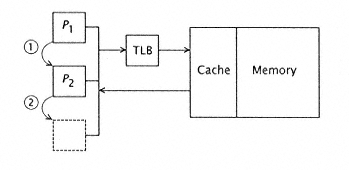
Figure 8.14
The SRMP. Only one processor issues
instructions at any one time. Control passes (1,
2) from processor to processor on context
switch or other event. Each processor has its
own I-cache. |
|
|
|
|
|
|
|
|
resources, such as floating-point hardware, can be shared by multiple processors together with a small high-bandwidth data cache which is used only for managing traffic to shared variables. The basic reason for SRMP is to facilitate context switches. With two processors, P1 and P2, control passes from P1 to P2 if there is a context switch in P1 (Figure 8.14). The context switch then is handled in P1 while P2 is active. Since the switch from P1 to P2 can be done in no more than a processor cycle, the SRMP offers high performance to environments that consist of many small, "lightweight" processes (or threads, see chapter 3). All processors share the same data space and (usually) the same TLB(s). |
|
|
|
|
|
|
|
|
There are two basic types of SRMP processor-switching protocols (Figure 8.15): |
|
|
|
|
|
|
|
|
1. Each processor shares resources (floating point, data cache, etc.) in a time-multiplex fashion [263]. |
|
|
|
|
|
|
|
|
2. A processor has control to varying degrees over all resources, so long as it does not encounter a pipeline stall. As soon as it encounters a stall of any typecontext switch, branch, run-on instruction, etc.control passes to another processor, while its stall or pipeline break is resolved in the background [9]. |
|
|
|
|
|
|
|
|
Under either of these control scenarios, the maximum achievable performance is: |
|
|
|
 |
|
|
|
|
Performancemaximum = 1/Dt, |
|
|
|
|
|
|
|
|
where Dt is the cycle time of either the shared resource or the maximum decode or maximum processing rate in the second case. |
|
|
|
|
|
|
|
|
Figure 8.16 illustrates a generic SRMP layout. The number of (register set) processors is chosen to optimize the cost-performance. |
|
|
|
|
|
|
|
|
SRMP makes reasonably good use of silicon, and could be a candidate arrangement for providing maximum processing power per unit of area on chip. This is illustrated in Study 8.1. |
|
|
|
|
|