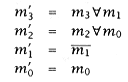|
|
|
|
|
|
|
Multiple Instruction Execution |
|
|
|
|
|
|
|
|
Multiple-issue processors were first studied by Tjaden [283] and later reviewed by Keller [159]. They have received a great deal of recent attention [149, 150, 227, 266]. Tjaden's result of 1970 is probably valid even today: without compiler support, multiple instruction execution is limited to about two instructions per cycle. |
|
|
|
 |
|
|
|
|
W. M. Johnson. Superscalar Microprocessor Design. Prentice-Hall, Englewood Cliffs, NJ, 1991. |
|
|
|
|
|
|
|
|
Pradeep K. Dubey. Exploiting Fine-Grain Concurrency: Analytical Insights in Superscalar Processor Design. PhD thesis, Purdue University, August 1991. |
|
|
|
|
|
|
|
|
B. R. Rau, J. A. Fisher. Instruction-level processing: History, overview and perspective. Journal of Supercomputing, Vol. 7, No. 1, January 1993. |
|
|
|
|
|
|
|
|
This is an excellent survey of the field. |
|
|
|
|
|
|
|
|
H. Dwyer, H. C. Torng. An out-of-order superscalar processor with speculative execution and fast, precise interrupts. Proceedings of Micro 25/SIGmicro Newsletter, December 1992. |
|
|
|
|
|
|
|
|
A nice treatment of an implementation of multiple instruction execution with precise interrupts. |
|
|
|
|
|
|
|
|
1. For the two-instruction example in Figure 7.12 (vector size = 64), find the total execution times assuming a chained and unchained vector ALU if the vector pipeline has eight stages: |
|
|
|
|
|
|
|
|
(a) What is the implied instruction memory bandwidth (bytes per cycle) for this computation? |
|
|
|
|
|
|
|
|
(b) Extend the code with the requisite VLD and VST. Now what is the implied data memory bandwidth (bytes per cycle) for this computation? |
|
|
|
|
|
|
|
|
2. Suppose we want to use m = 5 memory modules. Find the module address and the address within the module for the following (hex) addresses: |
|
|
|
|
|
|
|
|
(a) F37B90. |
|
|
|
|
|
|
|
|
(b) AA3347. |
|
|
|
|
|
|
|
|
3. Suppose the lower four bits of an address are designated m3, m2, m1, and m0. We hash t he bits to specify the module as follows (m¢3, m¢2, m¢1, m¢0 are the new address bits): |
|
|
|
|
|