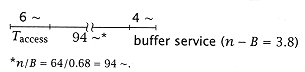|
|
|
| Table 7.3 The effects of vector bypass on performance. |
| | No Bypass | Limited Bypass | Full Bypass | | Buffer size and complexity | | | | | g | | | | | Total cycles for single VLD (64 reg), m = 16 n = 12 | | | | | Peforrmance relative to ideal vector ALU with 6 cycles startup (70 cycles total) | | | |
|
|
|
|
|
|
Suppose we increase the buffer size significantly so that we achieve n = B (no contention). Then we have: |
|
|
|
|
|
|
|
|
Note that we reduced the total time for the load only from 90 cycles to 86.5 cycles! With no bypassing at all, we would have: |
|
|
|
|
|
|
|
|
or a total time of 103 cycles. |
|
|
|
|
|
|
|
|
The buffer to support this case is a simple one-entry-per-module (16 total) buffer merely holding the deferred address and source id. |
|
|
|
|
|
|
|
|
From Table 7.3, it might appear that the "best" vector performance achievable would be in the range of 0.680.81 times maximum performance, based on memory system limitation. |
|
|
|
|
|
|
|
|
Our analysis in this example is based on two simultaneous VLD or VST. Insofar as some applications may not require two simultaneous memory accesses, this is a pessimistic performance projectione.g., for one access we would have (at g = 0): |
|
|
|
|
|
|
|
|
Here again, any request bypassing would improve performance. An obvious solution is to provide more vector registers, so that the VLDs would not be used in the next vector iteration. The problem here is the expense of (area occupied by) these additional registers. |
|
|
|
|
|
|
|
|
The preceding discussion is based on the assumption that we are not bypassing memory operations between vector instructions. That is, while we |
|
|
|
|
|