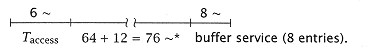|
|
|
|
|
|
|
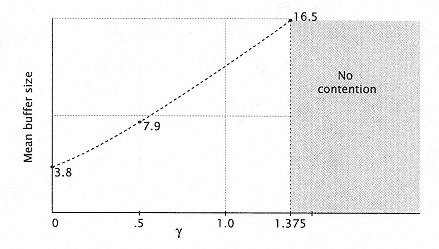
Figure 7.21
Expected buffer sizes required to achieve various bypass factors
g. (Physical buffer must be significantly larger.) |
|
|
|
|
|
|
|
|
1. Initial access (Taccess). |
|
|
|
|
|
|
|
|
2. Ideal memory access time (assume 64 cycles). |
|
|
|
|
|
|
|
|
3. Time lost to memory contention. |
|
|
|
|
|
|
|
|
4. Additional delay at the end of the load for the remaining (deferred) items in the buffer to be served. |
|
|
|
|
|
|
|
|
It is the last step (step 4) that can have a significant effect on overall performance. Typically, vector processors complete each instruction before beginning the next vector instruction. This allows external events such as interrupts to be handled at the completion of an instruction without having disturbed the state of the machine for successor instructions. This delay in draining the pipeline at the conclusion of each instruction can have a significant effect. Assume in the foregoing example that one cycle is required to put away each pending memory request. This allows the load and the stores that have been concurrently executing with the vector ALU operations to all complete before the next cycle of ALU and vector load/store instructions begin. If we allowed the vector ALU instructions to begin before the previous cycle's vector load and store instructions completed, we would have the danger that the vector ALU instructions over a period of time would catch up with or overrun the vector load/store instructions using data that has not yet been loaded into the vector registers or writing registers that have not yet had their current value stored in memory. |
|
|
|
|
|
|
|
|
Assume for the moment that the memory pipeline drains; that is to say, all vector instructions must be completed before a new set of vector instructions can begin. For example, we might have the following: |
|
|
|
|
|
|
|
|
*The effect of memory contention is estimated as ideal time´ n/B = 64/.84 = 76. |
|
|
|
|
|