|
|
 |
|
|
|
|
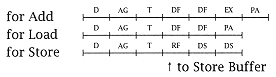
instructions are used in the example, the architecture could be R/M or L/S. This study also assumes an I-buffer with a primary path consisting of two 8-byte-wide entries and a target path of one 8-byte buffer entry. This study is taken from Rymarczyk [250]. |
|
|
|
|
|
|
|
|
Some coding practices (e.g., storing parameters in the instruction stream) degrade the performance of fully pipelined processors by forcing interlock mechanisms into serializing non-dependent code [250]. Many machines do not allow such practices by forbidding writes to code segments. Assuming such writes are allowed, we evaluate the effect of each (apparent) dependency in the following code: |
|
|
|
|
|
|
|
|
LD R5, 0[R6,R7]
ST ARGLIST, R5
LD R5, 4[R6,R7]
ST ARGLIST+4, R5
BAL R2, SUBROUTINE
ARGLIST: X
X |
|
|
|
|
|
|
|
|
The timing templates, excluding IF, are: |
|
|
|
|
|
|
|
|
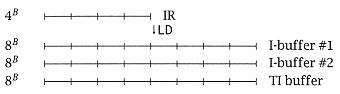
For I-fetch, an I-buffer is used consisting of two 8-byte memory word buffers (double word aligned) for in-line buffering, and one 8-byte buffer for TIF. The in-line IB is managed ''round robin"as soon as the last byte from an IB word is transmitted to the 4-byte IR, the fetch of the next eight bytes in the in-line path begins. (This will be two double words ahead, as the next double word ahead is in the other IB word.) The transmission of four bytes of IB to IR occurs while the current instruction is being decoded. Thus, at the beginning of the decode of *, an instruction that exhausted an IB word, a new fetch begins. (LD, ST, BAL are RM instructions, and are four bytes each.) |
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
The first load brings four bytes into IB #1, and IB #2 has just been loaded. Assume that either a store into one of the I-buffers or the anticipated next IF invalidates the contents of both IB #1 and #2. Also assume that an IF is checked against any addresses pending in the store buffer. Figure 4.30 shows the contents of the two I-buffers at various times. |
|
|
|
|
|