|
|
|
|
|
|
|
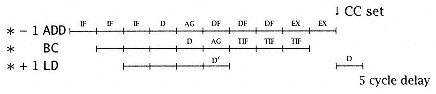
(b) Conditional Branch (BC) at *: |
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
In case 2, if we designate D¢ as the scheduled time for decoding the next instruction, there is a four-cycle delay attributable to the generation of the address for the next instruction and fetching that address into the instruction register. Thus, a four-cycle delay has been introduced, and the execution time for the unconditional branch is therefore five cycles. The conditional branch frequently represents an even worse case (case 2b). The instruction following the branch is not known (typically) until the execution of the instruction preceding the branch has set the condition code. On decoding the branch, the machine fetches the alternate instruction and then continues to fetch the in-line path (* + 1, * + 2,) begun earlier. Both paths are available once the condition code is known. Thus, as soon as * - 1 is completely executed, the instruction following the * can be decoded and the pipeline can resume operation. There is a five-cycle penalty time under the condition shown in case 2b. |
|
|
|
|
|
|
|
|
Unconditional/conditional branches are statistically the biggest causes of pipeline breaks (see Chapter 3). The pipelined processor assumes that all instructions lie in a line and that the sequence of instructions can be prefetchedfetched ahead of the instruction that is currently being decoded. When a branch occurs, however, the prefetched instructions are of no value and a new sequence of instructions must be fetched based upon the target instruction. The fetching of the target instruction in a branch instruction occurs at the same time a data fetch would have occurred in an arithmetic instruction. In the case of a conditional branch, the prefetched in-line instructions may still be of value, depending on the outcome of the instruction that is determining the condition (i.e., setting the condition code). It is useful to save prefetched in-line instructions, as well as to take the opportunity to fetch the target instruction in the timing slots usually reserved for a data fetch. Thus, we have at least one instruction from both paths when the condition code is resolved. Simple pipelined processors do not attempt to decode instructions beyond the branch until the condition code is known. More complex processors guess at the outcome of the branch and proceed down one of the paths, thereby saving the branch delay time when the guess is correct. |
|
|
|
|
|
|
|
|
Instructions frequently depend upon the result of predecessor instructions for an operand. The case that causes the most delay in a pipelined processor is when instruction * depends upon the immediately preceding instruction (* - 1) for an operand such as an index value that is used during an address generation operation in instruction *. The effect of this is illustrated next. |
|
|
|
|
|