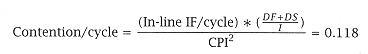|
|
|
|
|
|
|
Read Bypass Write: read request can bypass all writes in buffer; checking must be done to ensure that the current read request data is not in the write buffer already, to maintain consistency. For CBWA caches, the replaced line, if dirty, can be transferred to the write buffer concurrently with issuing the read request to memory. The processor restarts once the entire line is read into the cache. |
|
|
|
|
|
|
|
|
Read Bypass with Wrap Around: In addition to allowing a read to bypass writes, this scheme allows the missed word to be accessed first instead of waiting for the entire line to be returned to cache from memory; thus, the CPU can resume processing as soon as the first word is returned. |
|
|
|
|
|
|
|
|
Based on the preceding description, we analyze all three cases for CBWA policy and the latter two for the WTNWA policy. Since WTNWA does not have line writes, the simple scheme does not apply. The basic idea behind schemes 2 and 3 is to reduce the time the processor is waiting for read data. For these cases, it is possible to have contention between previous read and write requests in progress and the current read request. The implications of the different schemes on CPI are presented in the CPI section, and a performance comparison is done in the analysis section. |
|
|
|
|
|
|
|
|
Given a fixed area to implement the cache, we can first qualitatively consider whether to use the unified or the split cache scheme. Unified cache offers a lower overall miss rate, but we must consider the amount of contention delay due to conflicting data and instruction accesses. A split cache offers higher bandwidth, since separate data paths exist for instruction and data accesses. However, we must provide the additional area required for the data paths and a higher overall miss rate. As a rough approximation, we assume that for a split cache 10% of the cache area is utilized by data paths. |
|
|
|
|
|
|
|
|
Unified Cache Contention Modeling |
|
|
|
|
|
|
|
|
In a unified cache, the designer must evaluate the performance penalty resulting from contention at the cache interface that is due to conflicts between data accesses and instruction accesses. In calculating the contention, one needs to take the actual CPI into consideration, since many of the instruction requests are from branches that degrade the CPI of the processor. Only in-line reference stream and executed instructions need to be considered, since an instruction that is not executed cannot result in contention. We can model the contention as performed in study 5.4. However, we must break the analysis into CBWA and WTNWA cases. |
|
|
|
|
|
|
|
|
For CBWA, the data traffic needs to include both data fetch and data store, since, unlike WTNWA, both access the cache. Since the on-chip cache can be accessed every cycle, we should take CPI into account and calculate the probability of contention per cycle: |
|
|
|
|
|