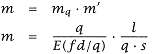|
|
|
|
|
|
|
where Prob (f = n) is the probability that a file access consists of an access to n physical disk blocks. Only one disk is accessed for f = 1, two disks are accessed for f = 2, and q disks are accessed for f ³ q. |
|
|
|
|
|
|
|
|
Then m, the effective number of independent servers, is: |
|
|
|
|
|
|
|
|
for a (q, 1) system. We refer to the number of independent servers due only to distribution as mq and 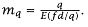 . . |
|
|
|
|
|
|
|
|
We can generalize for composite (q,s) systems the number of independent sub-systems, m¢: |
|
|
|
|
|
|
|
|
and each (dd) subsystem is as above, so that m, the total number of independent servers, is: |
|
|
|
|
|
|
|
|
Including m¢ in determining m is often unrealistic. Once an access is made to a file, it is highly probable that subsequent accesses will also go to it. Using m¢ is a best-case estimate of m and hence r. More realistic estimates will be discussed later. |
|
|
|
|
|
|
|
|
In the following sections, we look at the three types of multiple disk organizations: independent, distributed (striped), and synchronized. We evaluate the Ts, Ttransfer, and the occupancy r for representative configurations. |
|
|
|
|
|
|
|
|
Later, we use this analysis to determine the request waiting time Tw and overall composite disk system performance. We illustrate this, following the work of Reddy and Banerjee [244], by considering a disk arrangement using 16 disk drives (Tlatency = 17.5 ms, Tread = 2.6 ms for a 4KB block) and a transaction-type workload: 70% of the requests are for 1-block files, and 30% of the requests are for multiple-block filesuniformly distributed from 2 to 16 blocks. This illustrative data will later be the basis of a study of a composite disk system (studies 9.5 and 9.6). |
|
|
|
|
|
|
|
|
The model of the processor(s) that uses the disk ensemble is also important. Multiple independent workstations tend to access multiple independent servers, more so than a single multiprogrammed processor. In fact, in the latter case, probably the most conservative assumption is that all requests are directed to a single file server (which itself may consist of multiple disks, m¢ = 1). In the case of multiple processors, there is an argument for assuming either (optimistically) a uniform distribution of requests over the independent servers or (conservatively) some clustering of requests about a smaller number of servers. |
|
|
|
|
|