|
|
|
|
|
|
|
A SRMP processor is busy for one cycle out of every 3.56 cycles of execution. It is idle for 2.56 cycles each instruction. Now we use our null-binomial model to predict performance. (Note: requests are not immediately resubmitted, as the stall must be resolved.) |
|
|
|
|
|
|
|
|
Overall, the SRMP achieves 1.37 CPI while the pipelined processor achieves 2.25 CPIa 1.64-times speedup. Of course, the SRMP requires some additional area (three register sets), partitioning and scheduling overhead, etc., so the net gain is less. |
|
|
|
|
|
|
|
|
8.8 Memory Coherence in Shared Memory Multiprocessors |
|
|
|
|
|
|
|
|
Probably no area of shared memory multiprocessor architecture has been more studied and discussed than memory coherence. Memory coherence is the essential ingredient in creating a shared memory multiprocessor. There are many methods or protocols for achieving a coherent memory picture, but the control of each protocol may be complex and the nomenclature is frequently confusing. |
|
|
|
|
|
|
|
|
The fact that each node in a multiprocessor system possesses a local cache leads to the cache coherency problem. Since the address space of the processors overlaps, different processors can be holding (caching) the same memory segment at the same time, and possibly modifying the same physical memory location simultaneously. Therein lies the cache coherency problemto ensure that all processors (caches) see the same, most updated copy of data. The protocol that maintains the consistency of data in all the local caches is called the cache coherency protocol. |
|
|
|
|
|
|
|
|
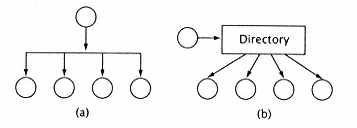
Figure 8.17
Snoopy and directory-based protocols. (a)
Broadcast (snoopy) protocols: on a write to a
shared line, all processors are notified. (b)
Networked or directory-based protocols: on a write to a
shared line, only processors that have a copy of
the line are notified. |
|
|
|
|
|