|
|
|
|
|
|
|
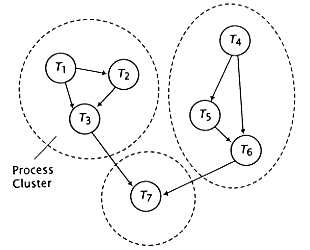
Figure 8.3
Grouping tasks into process clusters. |
|
|
|
|
|
|
|
|
Moreover, the overhead time is: |
|
|
|
|
|
|
|
|
1. Configuration dependent. Different shared memory multiprocessors may have significantly different task overheads associated with them, depending on cache size, organization, and the way caches are shared. |
|
|
|
|
|
|
|
|
2. Overhead may be significantly different depending on how tasks are actually assigned (scheduled) at run time. A task returning to a processor whose cache already contains significant pieces of the task code or data set will have a significantly lower overhead than the same task assigned to an unrelated processor [268, 290]. |
|
|
|
|
|
|
|
|
Increased parallelism usually corresponds to finer task granularity and larger overhead. Consider the control graphs in Figure 8.3. Clustering is the grouping together of sub-tasks into a single assignable task. Clustering is usually performed both at partitioning time and during scheduling run time. The reasons for clustering during partition time might include: |
|
|
|
|
|
|
|
|
1. The available parallelism exceeds the known number of processors that the program is being compiled for. |
|
|
|
|
|
|
|
|
2. The placement of several shorter tasks that share the same instruction and/or data working set into a single task provides lower overhead. |
|
|
|
|
|
|
|
|
The detection of parallelism itself in the program is achieved by one of three methods: |
|
|
|
|
|
|
|
|
1. Explicit statement of concurrency in the higher-level language, as in the use of such languages as CSP (communicating sequential processes) [131] or Occam [75], which allow programmers to delineate the boundaries among tasks that can be executed in parallel, and to specify communications between such tasks. |
|
|
|
|
|
|
|
|
2. The use of programmer's hints in the source statement, which the compiler may choose to use or ignore. |
|
|
|
|
|