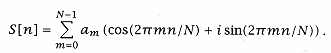|
|
|
|
|
|
|
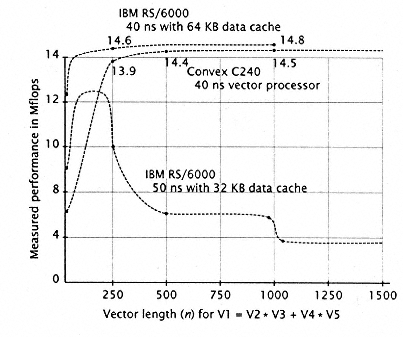
Figure 7.55
Performance of two 40ns processors: the Convex 240 (a
vector processor) and the IBM RS/6000 (a superscalar
processor). A version of this processor was also measured
with a 50ns cycle and a (half-sized) 32 KB data cache.
Data from Simmons and Wasserman [258]. |
|
|
|
|
|
|
|
|
other words, given an array of data of N sample points, where N is a power of 2, the sample array can be approximated as the sum of sines and cosines: |
|
|
|
|
|
|
|
|
For fixed frequency m, n (the time) varies from 0 to N - 1; then the sine and cosine functions trace out exactly m complete cycles. We need to solve for the Fourier coefficients am. |
|
|
|
|
|
|
|
|
This algorithm requires N complex multiplies for each coefficient and appears to be an N2 algorithm. Because of the regularity of the matrix, the problem can be subdivided: the rows at the bottom half of the matrix are duplicates of the rows at the top half of the matrix, except for the signs in odd-numbered columns. Thus, the matrix may be reorganized and reduced by this reorganization to N logN complex multiplies. |
|
|
|
|
|
|
|
|
Table 7.10 indicates the performance, in cycles per iteration, for the MIPS R3000 33 MHZ and a 64KB external cache for a variety of sample sizes. This can be compared with the performance as measured on a Cray-II, taken from Bailey [24]. This is plotted in Figure 7.56. Conventional processors, all of whose data accesses pass through a data cache, may experience significant performance degradation on large scientific problems. Vector processors avoid the problem by excluding vector data from entry into the data cache and forcing all such structured references to main memory. |
|
|
|
|
|