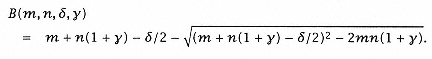|
|
|
|
|
|
|
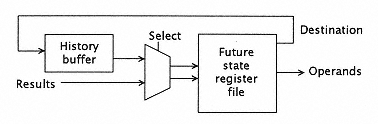
Figure 7.50
History buffer method. |
|
|
|
|
|
|
|
|
set. Of course, since the restoration of the future file state to include the history file information may be somewhat time-consuming, the history file technique adds an overhead to exception handling. |
|
|
|
|
|
|
|
|
In order to handle multiple load/stores, adequate cache bandwidth must be available. This is especially true for the data cache. For instruction caches, bandwidth can be achieved by simply lengthening the access path, since instructions are accessed in-line and a wide instruction path generally provides adequate bandwidth. The effectiveness of such a wide access depends on the frequency and placement of branch instructions, as well as the relative frequency of taken branches. As in the rest of superscalar organization, compiler technology plays a key role in the achievement of efficient code execution, as can readily be seen in the effectiveness of a relatively large I-fetch. |
|
|
|
|
|
|
|
|
Data caches generally require interleaved caches to provide adequate bandwidth since the number of accesses per cycle is generally relatively low, even to support high issue rates. It ought to be possible to support these issue rates with reasonable degrees of interleaving. In chapter 6, we saw that two load/store units were relatively conflict-free (only about 3% interference) with 8-way interleaving. |
|
|
|
|
|
|
|
|
In principle, it ought to be possible to combine the bypassing techniques used with vector processors mentioned earlier in this chapter with the interleaving techniques described previously and in chapter 6. The bypassing of requests represents another way to avoid conflicts in data caches. If requests are bypassed, we can determine their effectiveness by combining the delta-binomial and gamma-binomial equations developed earlier into a generalized model of processor memory performance called the gamma-delta (g, d) binomial model: |
|
|
|
|
|
|
|
|
Following the discussion of chapter 6, |
|
|
|
|
|
|
|
|
where z is the number of requestor sources that can occur in a processor cycle times the number of processor cycles per cache cycle. |
|
|
|
|
|