|
|
|
|
|
|
|
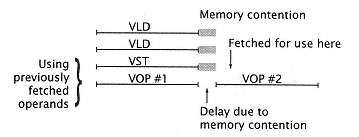
Figure 7.26
The effect of memory contention on vector performance. |
|
|
|
|
|
|
|
|
arithmetic pipeline, the vector startup might be six cyclesfour cycles for the operation plus two cycles for bus transit of data. So, in this case, the vector startup cost is 6~, and thus n1/2» 6 ~. |
|
|
|
|
|
|
|
|
Vector processors access data directly from memory, giving them a significant advantage in accessing complex or large-stride data arrays. However, the memory system necessarily experiences some contention under heavy referencing conditions. This contention causes the vector registers to be loaded and stored more slowly than vector instructions are executed through the vector ALU. The vector ALU in general, then, is waiting for the vector registers to be made available. The delay corresponds to the memory contention; see Figure 7.26. |
|
|
|
|
|
|
|
|
For memory-limited processors, n1/2 may be determined by the sum of memory access time, contention, and buffer putaway completion. Generally, |
|
|
|
|
|
|
|
|
n1/2» max [vector arithmetic startup cycles, vector memory overhead cycles]. |
|
|
|
|
|
|
|
|
Since the vector processor is operating directly from memory, and it is assumed that the vector load and store traffic is being overlapped with vector arithmetic, we can asymptotically realize the vector speedup of perhaps 4 or 5. Delays in accessing memory due to memory conflicts accumulate during the course of vector arithmetic operations. This has the effect of slowing down the vector processor, making it impossible to achieve its asymptotic speedup performance. |
|
|
|
|
|
|
|
|
All this may seem to paint a discouraging picture concerning vector processor performance, but this is somewhat deceptive. While the vector processor speedup is indeed limited to values significantly below the asymptotic maximum speedup of 4 or 5, speedups of 23 are achievable for applications that have significant vector content in their code. Moreover, the basis of the speedup that we have described is an idealized simple pipelined processor. This processor itself is, in general, unable to sustain its unit performance over a variety of large-stride vector code. Thus, the speedup, in practical situations, of a vector machine over a simple pipelined machine may be significantly greater than the factors of 2 or 3 anticipated here. We discuss this later in this chapter. |
|
|
|
|
|