|
|
|
|
|
|
|
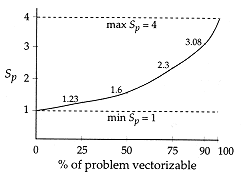
Figure 7.22
Speedup of an idealized vector
processor vs. percentage of a
program that is vectorizable.
Assume that the maximum speedup
over a pipelined processor is Sp = 4
and that the vector code is ideal (long
vectors, no memory contention). |
|
|
|
|
|
|
|
|
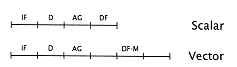
Figure 7.23
Timing templates for pipelined
(scalar) processor and vector
processor. The scalar processor
accesses data (DF) from the data
cache; the vector processor
accesses data directly from
memory (DF-M). |
|
|
|
|
|
|
|
|
Figure 7.22 plots the speedup vs. the percent of vectorizable code for this illustration. |
|
|
|
|
|
|
|
|
The depth of the pipeline itself also limits the effective speedup of the vector processor. A pipelined or scalar processor accesses its operands from data cache. Because of structured data accesses, the vector processor accesses directly from memory. This introduces extra cycles to the timing template of the vector processor (Figure 7.23). It may also be true (although it need not) that the vector processor's execution unit pipeline would be longer than the scalar processor's. Since predefined sequences of operations are expected in vector machines, there is a tendency on the part of the designers not to emphasize and minimize execution latency, whereas the scalar processor designer emphasizes latency even if the processor cannot match the execution bandwidth of the vector processor. For both these reasons, the scalar processor tends to have a shorter timing template than the vector processor. This has two effects: |
|
|
|
|
|
|
|
|
1. It puts the vector processor at a performance disadvantage in processing branch instructions and similar code sequence interruptions. |
|
|
|
|
|
|
|
|
2. It limits the speedup available to the vector processor on vector instructions that refer to short vectors. |
|
|
|
|
|
|
|
|
Hockney and Jesshope [132] characterize the performance of vector processors with two parameters: R¥, and n1/2. R¥= 1/Dt, or one over the basic cycle time of the vector pipeline. This is a measure of the maximum vector arithmetic execution rate that the processor can sustain in the absence of |
|
|
|
|
|