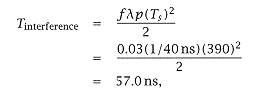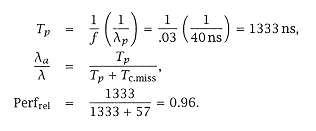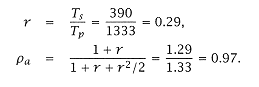|
|
|
|
|
|
|
Assume that the processor and cache of study 6.3 are now nonblocking (CBWA). We will now access the processor-cache-memory performance using both methods outlined above. |
|
|
|
|
| | |
|
|
|
|
Tline access(1 + w) = Ts = 390 ns; |
|
|
|
| | | |
|
|
|
|
|
|
so that Tmiss = 57 ns and relative performance is |
|
|
|
|
|
|
|
|
This is also the relative performance, since ra is the achieved occupancy of the processor (not the memory). |
|
|
|
|
|
|
|
|
6.8.11 Interleaved Caches |
|
|
|
|
|
|
|
|
Interleaved caches can be handled rather straightforwardly, and are almost completely analogous to interleaved memory. Generally, we use the d-binomial to determine the realized performance from a system involving interleaved caches. This is especially effective and appropriate where we are modeling interleaved data caches which are dominated by read traffic. Generally, the reads appear unbuffered to the processor, and the processor slows down on a read conflict. If there is a mix of buffered and unbuffered references to the cache, we need a more powerful model of processor-cache interaction. We call this model the g-d-binomial model, and we will introduce it in the next chapter when we cover superscalar machines. The following example illustrates the use of the delta binomial for interleaved caches. |
|
|
|
|
|