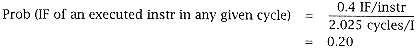|
|
|
|
|
|
|
data dependencies will interlock, or "lock out," IF). Thus, there are ample cycles available to "fit in" the 126 requests (i.e., the 100 ´ 1.26 cache CPI developed earlier). |
|
|
|
|
|
|
|
|
Which accesses cause delay? Since contention cannot arise between TIF and DF (TIF uses a DF slot), the primary source will be between in-line and executed instructions whose execution is delayed by a DF. (Delay cannot arise if a nonexecuted instruction is delayed.) Assume that each requestor source can make at most one access in a cycle and that the probability of an access corresponds to the expected number of accesses per cycle from that source. |
|
|
|
|
|
|
|
|
We can then model contention by first computing: |
|
|
|
|
|
|
|
|
The probability of an executed instruction, eliminating the excess I-traffic, is just I/P = 0.4 (see study 5.1). The number of cycles/I as discussed previously is 2.025. Instructions that are fetched but not executed are those fetched in anticipation of a branch. If the branch takes the other path, any contention delay incurred in fetching these nonexecuted instructions cannot have a performance effect. We eliminate this excess instruction and target traffic, which (since they are not executed) cannot cause delay, and |
|
|
|
 |
|
|
|
|
Prob (DF or DS in any given cycle) |
|
|
|
|
|
|
|
|
= (DF or DS/I) divided by CPI = (0.34 + 0.20)/2.025 = 0.27. |
|
|
|
|
|
|
|
|
Now assuming that IF and DF are independent events, the probability of a conflict in any cycle is: |
|
|
|
|
|
|
|
|
Prob (IF/cycle) Prob (DF/cycle) = (0.20) (0.27) = 0.05. |
|
|
|
|
|
|
|
|
This can be summarized as |
|
|
|
|
|
|
|
|
where IF/I is I/P (the expected number of in-line I-fetches per instruction), (DF + DS)/I is the expected number of data references per instruction, and CPI is computed without inclusion of any cache delays. |
|
|
|
|
|
|
|
|
Actually, for many cases, a delay of an executed instruction fetch for a cycle may not cause delay, but a sequence of such delays (two or more) causes delay. However, we use the conservative estimate of 0.06 for cache contention. This gives a total delay estimate of 2.02 CPI ´ 0.05 = 0.10 CPI. This analysis apparently violates our chapter 4 timing rule: "always design for peak (here, one cycle per instruction) execution rates." The point of this analysis is to recognize the role of branches both in creating the contention problem and in (partially) relieving the problem. |
|
|
|
|
|
|
|
|
The 1.26 cache CPI and execution rate of one CPI are inconsistent statements, since the first includes branch effects and the second does not. Once we have accepted a branch strategy frequency, we can use this information in a consistent way. |
|
|
|
|
|