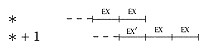|
|
|
|
|
|
|
(v) Data dependencies play a role similar to run-on instructions. Consider: |
|
|
|
 |
|
|
|
|
* ADD R5, ALPHA
* + 1 ADD R5, BETA |
|
|
|
|
|
|
|
|
The second ADD instruction uses as an argument the result of the first instruction. |
|
|
|
|
|
|
|
|
Thus, * + 1 is delayed a cycle by the dependency. Note that in this case, as is a common occurrence, the delay required by in-order EX masked part of the data dependency. For machines that require in-order EX we'll ignore data dependency effects since they are largely accounted for as a run-on effect. |
|
|
|
|
|
|
|
|
Let us assume that the sum of run-on effects and dependency effects adds another 0.6 cycles per instruction. For a more complete analysis, we could use the statistics of Chapter 3 and evaluate each of the run-on dependencies using a list of the run-on delays. Depending on the environment and the machine parameters, run-on effects either may be limited or may dominate performance considerations. The 0.6 CPI assumed here is a low estimate as to the run-on effects in a simple pipelined processor. It might correspond to a simple processor in an application environment dominated by systems code, where the frequency of run-on arithmetic instructions is low. |
|
|
|
|
|
|
|
|
In summary, we are now at |
|
|
|
|
|
|
|
|
2.22 + 0.6 = 2.82 CPI |
|
|
|
|
|
|
|
|
without including the effects of cache miss or other memory-related penalties. |
|
|
|
|
|
|
|
|
Study 4.4 Improving Branch Performance |
|
|
|
|
|
|
|
|
Assumptions: |
|
|
|
|
|
|
|
|
In this study, we again use the timing template of study 4.2, and the simple nonpredictive, nonbuffered branch type strategy of study 4.3. |
|
|
|
|
|
|
|
|
From study 4.3, we see that the performance cost of branches can be high. We now evaluate the effects of two strategies for minimizing the branch penalty: early CC setting and delayed branch. We use the processor timing outlined in studies 4.2 and 4.3. |
|
|
|
|
|