|
|
|
|
|
|
|
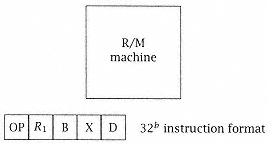
Figure 4.10
R/M machine. All instructions follow R1
¬ R1 OP Mem[D + [RB] + [RX]] or R1 ¬ R2 OP
R3 (where R2 and R3 replace RB and RX). |
|
|
|
|
|
|
|
|
that stage until the dependency is removed. Thus, the decode of instruction 3 and all subsequent instructions is delayed by three cycles. |
|
|
|
|
|
|
|
|
The D for instruction 4 is delayed so as to preserve the in-order decoding of instructions. In resolving the issue of additional total delay or marginal delay for sequences of code, we use the first instruction as a reference. Its total allocated latency is nine cycles. Instruction 2 is nominally scheduled to complete at the end of cycle 8, but is delayed by three cycles. Instruction 3 is an RR instruction that needs no AG or DF. It completes (despite its dependency) by the end of cycle 13 (the sum of its scheduled time plus already incurred delay), so no further overall delay is encountered. The same is true for instruction 4 decode, but its DS is additionally delayed. The target of the branch incurs further delay, as the target address is the same as the store address in instruction 4. This is detected as a store dependency and the TIF does not occur until the DS is complete. Since the CC is set by instruction 3, the in-line path, if selected, is not delayed by this interlock. |
|
|
|
|
|
|
|
|
Instructions 2 through 5 could be queued up in the decoder while dependencies are being resolved. What actually happens is that instruction fetch ceases when a prior instruction is held in the decoder. The dependency analysis remains the same (Table 4.6). |
|
|
|
|
|
|
|
|
Study 4.3 Internal Performance |
|
|
|
|
|
|
|
|
This study evaluates processor performance of the processor in study 4.2, now taking into account the following effects: |
|
|
|
|
|
|
|
|
3. Run-on instructions (instructions with long execution times). |
|
|
|
|
|